
Museum ist nicht gleich Museum
Gepostet am 17. April 2022 • 5 Minuten • 1030 Wörter
Museen sind vielfältig: kleine Dorfmuseen, ein großes Technikmuseum oder eine Kunstausstellung. Gerne würden wir sie in passende Kategorien sortieren und übersichtlich ablegen. In diesem Blogpost möchte ich einen Blick darauf werfen, wie gut diese Kategorien passen - und welche Alternativen wir haben.
Im Detail ist unsere Welt immer kompliziert. In der Theorie klingt es ganz einfach: Wir ordnen jedem PoI (Point of Interest) einer Kategorie zu. Was machen wir jetzt aber mit dem Kunsthistorischen Museum? Neben der Ausstellung hat es vielleicht noch ein Café, einen Shop und befindet sich in einem historischen Gebäude. Und selbst, wenn wir diese “Anhängsel” vernachlässigen - es liegt wahrscheinlich eher irgendwo zwischen Kunst- und Geschichtsmuseum.
 Midjourney vs. Reality: So stellt sich Midjourney das Kunsthistorische Museum in Magdeburg vor.
Midjourney vs. Reality: So stellt sich Midjourney das Kunsthistorische Museum in Magdeburg vor.
Im Redaktionshandbuch für die PoI-Datenbank des Landes Brandenburg (genauer der TMB Tourismus-Marketing Brandenburg GmbH) werden 9 verschiedene mögliche Tags für Museen genannt:
- Stadt-, Regional- und Heimatmuseum (z.B. Städisches Museum Eisenhüttenstadt)
- Geschichts- und Gewerbemuseum (z.B. DDR-Geschichstmuseum, Modemuseum, Ziegeleimuseum)
- Schloss- und Sakralmuseum (z.B. Schloss Caputh, Schloss Rheinsberg, Kloster Neuzelle)
- Kunst- und Literaturmuseum (z.B. Kunstmuseum Dieselkraftwerk Cottbus, Museum Brecht Weigel Haus)
- Technikmuseum (z.B. Wettermuseum Lindenberg, Ziegeleipark Mildenberg)
- Naturkundemuseum (z.B. Naturkundemuseum Potsdam)
- Agrar- und Forstmuseum (z.B. Agrarhistorisches Museum Schlepzig)
- Mahn- und Gedenkstätte (z.B. Gedenkstätte und Museum Sachsenhausen)
- sonstiges Museum (z.B. Sportmuseum, Artistenmuseum)
Diese Unterteilung basiert auf den Kategorien des Museumsverband des Landes Brandenburg e. V.
Im letzten Jahr haben Iana Palacheva und ich einige Analysen der Daten in der DAMAS Datenbank gemacht. Die Kategorie “Kultur”, in der sich auch die Museen befinden, stellt mit 2199 Einträgen hinter “Übernachtungen” und “Essen & Trinken” die drittgrößte Kategorie in der Datenbank.
Unter diesen Einträgen sind 466 Museen verzeichnet, von denen fast die Hälfte in die Kategorie Stadt-, Regional- und Heimatmuseum fallen. Mit 7 Museen bilden Agrar- und Forstmuseen die kleinste Kategorie.
Um einen genaueren Einblick in ein Museum zu bekommen, nutzen wir zusätzlich zum Titel auch den Beschreibungstext. In diesen Texten sind oft verschiedene Attraktionen, Ausstellungen und Besonderheiten beschrieben. So bekommt man einen besseren Eindruck von dem Museum. Der Museumspark Rüdersdorf hat mit 4004 Zeichen den mit Abstand längsten Beschreibungstext. Die meisten Texte sind jedoch kürzer als 1000 Zeichen. Der kürzeste Beitrag beschreibt das Museum Flugplatz Welzow:
Auf dem Verkehrslandeplatz Welzow befindet sich auf 450 Quadratmetern ein Museum, dass die Luftfahrtgeschichte des Flugplatzes von den Anfängen bis zur Gegenwart präsentiert.”
Nun wollen wir Ähnlichkeiten zwischen diesen Texten herausfinden. Eine Voraussetzung ist also, dass wir in irgendeiner Art und Weise mit Ihnen rechnen können. Dafür müssen wir sogenannte Embeddings von den Texten erstellen. Das sind lange Vektoren - also Zahlenreihen. Welche Informationen sich genau in ihnen wiederfinden, verbirgt sich hinter der Magie einer Künstlichen Intelligenz (natürlich ist das etwas vereinfacht).
Für die Erstellung dieser Vektoren wurde das Luminous-base Sprachmodell von dem deutschen Anbieter Aleph Alpha genutzt. Neben vielen anderen Schnittstellen fürs Zusammenfassen von Texten, das Beantworten von Fragen oder das Fortschreiben von einem Textanfang werden hier auch zwei Schnittstellen für das Embedden von Texten - also das Umwandeln in Zahlenketten - bereitgestellt.
Rohe Embeddings: Dieser ist eher technisch gedacht und gibt die interne Repräsentation des Sprachmodells zurück. Wir nutzen hier quasi das rohe Sprachmodell.
Semantische Embeddings: Dieser ist weiter verfeinert und darauf optimiert, die semantische Bedeutung eines Textes zu erfassen. Für eine vereinfachte Anwendung können hier auch die 5120 Zahlen in 128 Werte heruntergerechnet werden. Die soll laut Dokumentation Genauigkeitseinbußen von 4-6% zur Folge haben, dafür aber in der weiteren Verarbeitung deutlich performanter sein.
Für jedes Museum in Brandenburg lassen wir einen dieser Vektoren errechnen, die die semantische/inhaltliche Bedeutung widerspiegeln sollen. Wir könnten an dieser Stelle den Titel oder auch den ersten Satz etwas höher gewichten und in gewisser Weise technisch unterstreichen, aber auch ohne weiteres Verfeinern, bekommen wir schon sehr interessante Ergebnisse.
Um diese aber auch visualisieren zu können, brechen wir die 128 Dimensionen auf nur noch zwei Zahlen herunter und nutzen diese als x- und y-Koordinaten in einem Streudiagramm. Natürlich geht auch hier etwas Genauigkeit verloren, das nehmen wir aber gerne in Kauf - der besseren Verständlichkeit wegen.
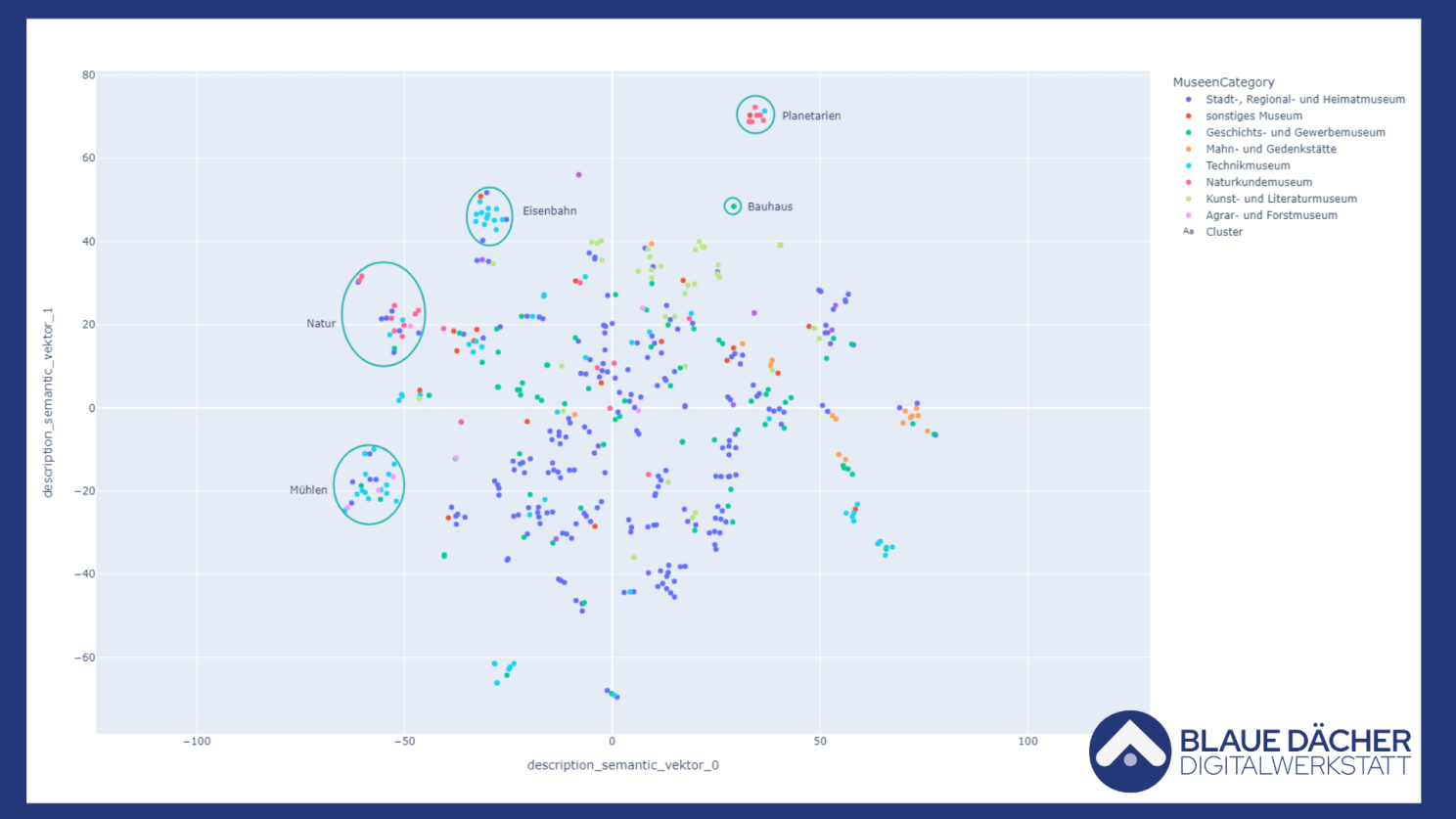 Visaulisierung der Zahlenketten für Museen
Visaulisierung der Zahlenketten für Museen
In dieser Grafik lassen sich nun klare (und wenige klare) Cluster ablesen. An den Rändern lassen sich diese auch gut einem bestimmten Inhalt zuordnen. Ich habe hierzu ein paar Beispiele eingefügt: Planetarien lassen sich besonders gut von den anderen Museen separieren - obwohl sie teilweise als Naturkunde- und teilweise als Technikmuseum verzeichnet sind. Auch für Mühlen findet sich ein gesondertes Cluster wieder, welche vorher sehr vielfältig den Kategorien Technikmuseem, Regionalmuseem, Agramuseen und auch Geschichtsmuseen zugeordnet war.
Diese Arbeit ist bisher sehr mühsam und aufwändig. Da man hierzu (momentan nach Augenmaß) die Cluster identifizieren und dann die einzelnen Einträge und ihre Beschreibungstexte lesen und gemeinsame Merkmale identifizieren muss. Bei einigen Clustern sind diese gemeinsamen Merkmale sehr offensichtlich, besonders bei der Unterscheidung zwischen verschiedenen Heimatmuseen können die Unterschiede aber tief im Beschreibungstext vergraben sein.
Bei Interesse schreibe ich gerne einen weiteren Blogpost, wie diese Segmentierung auch maschinell erfolgen kann, um automatisiert diese Museumscluster zu finden.
Mit unseren Zahlenreihen für die verschiedenen Museen lassen sich diese natürlich auch gut miteinander vergleichen. Wir können also zu jedem Museum die nächsten Nachbarn - nicht geographisch gesehen, sondern inhaltlich - finden. Oder ein System trainieren, welches basierend auf einer Freitextfrage ein passendes Museum aussucht.
Du hast Interesse, gemeinsam mit uns konkrete Anwendungsfälle für Künstliche Intelligenz zu pilotieren und bei der Umsetzung ganz vorne mit dabei zu sein, wir freuen uns auf eine Nachricht. Natürlich freuen wir uns auch über jegliche Ideen und Anregungen für mögliche Datensätze oder Analysen.
Vielen Dank an die TMB und besonders an Marcel Tischer und Maria Falkenberg für die Bereitstellung der Daten aus der DAMAS Datenbank.
TLDR:
- Museen sind vielfältig. Wir können sie in Kategorien sortieren, aber die Kategorien passen nicht immer.
- Die TMB hat eine Datenbank mit Informationen zu allen Museen in Brandenburg aufgebaut. Diese Daten können für verschiedene Analysen genutzt werden.
- In der DAMAS Datenbank sind 466 Museen verzeichnet, von denen fast die Hälfte in die Kategorie Stadt-, Regional- und Heimatmuseum fallen.
- Für jedes Museum in Brandenburg lassen wir einen Vektor errechnen, der die semantische/inhaltliche Bedeutung widerspiegeln soll.
- Es lassen sich nun klare (und wenige klare) Cluster ablesen. An den Rändern lassen sich diese auch gut einem bestimmten Inhalt zuordnen.